


Papers Xplained 📚: Self-Play Fine-Tuning, TinyLlama
A deep dive into two of the top papers from the 1st week of January 2024

Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models 💪

This recent paper has introduced an innovative approach to enhance Large Language Models (LLMs). This method, termed Self-Play fIne-tuNing (SPIN), begins with a model already improved through Supervised Fine-Tuning (SFT). The novelty of SPIN lies in its unique self-play mechanism. This involves the LLM engaging in an interactive learning process with its previous iterations. Through this self-play, the model generates and evaluates its own training data, differentiating between its own responses and those derived from human-annotated data.

One of the standout features of SPIN, as highlighted in the paper, is its ability to enhance LLMs without the need for additional human-annotated data. This method effectively leverages existing data to elevate a basic LLM to a more sophisticated level. Theoretical analysis provided in the paper supports the effectiveness of SPIN, indicating that the optimal training outcome aligns with the target data distribution.
Method
SPIN consists of two steps:
Training the Main Player
The authors first talk about training the main player to differentiate between responses from LLMs and responses from humans. Motivated by integral probability metric (IPM), their objective function helps the main player get better at telling whether a response is from a human or an LLM. The scoring is based on how well the main player can guess the difference between human and LLM responses. The goal for the main player is to maximize the score by making accurate guesses.
Updating the Opponent Player
Firstly, the main player, after being trained, can differentiate between data from the actual LLM (opponent player's distribution) and real human data. It does this by assessing two responses to the same prompt and deciding which one seems more like it came from real data.
The goal for the opponent player then is to become better at creating responses that are hard for the main player to distinguish from real human data. This is done by trying to maximize an expected value in the responses it generates. To keep the opponent player's responses from deviating too much and to stabilize the training, the authors use a technique called Kullback-Leibler (KL) regularization.
Experiments
Model and Dataset Used: The experiments were conducted on zephyr-7b-sft-full, a fine-tuned LLM based on Mistral-7B using the SFT dataset Ultrachat200k.
Comparison with Standard SFT Training:
Standard continued training using SFT on the Ultrachat200k dataset showed a performance plateau or even diminished scores.
In contrast, the SPIN method consistently improved the performance of zephyr-7b-sft-full across successive iterations.
This was achieved even though SPIN leveraged only a 50k subset of the Ultrachat200k dataset.
Performance Improvements:
SPIN improved the base model's average score from 58.14 to 63.16 on the HuggingFace Open LLM Leaderboard.
There was a notable improvement of over 10% in scores on specific benchmarks like GSM8k and TruthfulQA.
On MT-Bench, the score increased from 5.94 to 6.78.
Comparison with Other Enhanced Models: SPIN's results were comparable to models trained on an additional 62k preference dataset. This comparison held true on both the Open LLM leaderboard and MT-Bench.
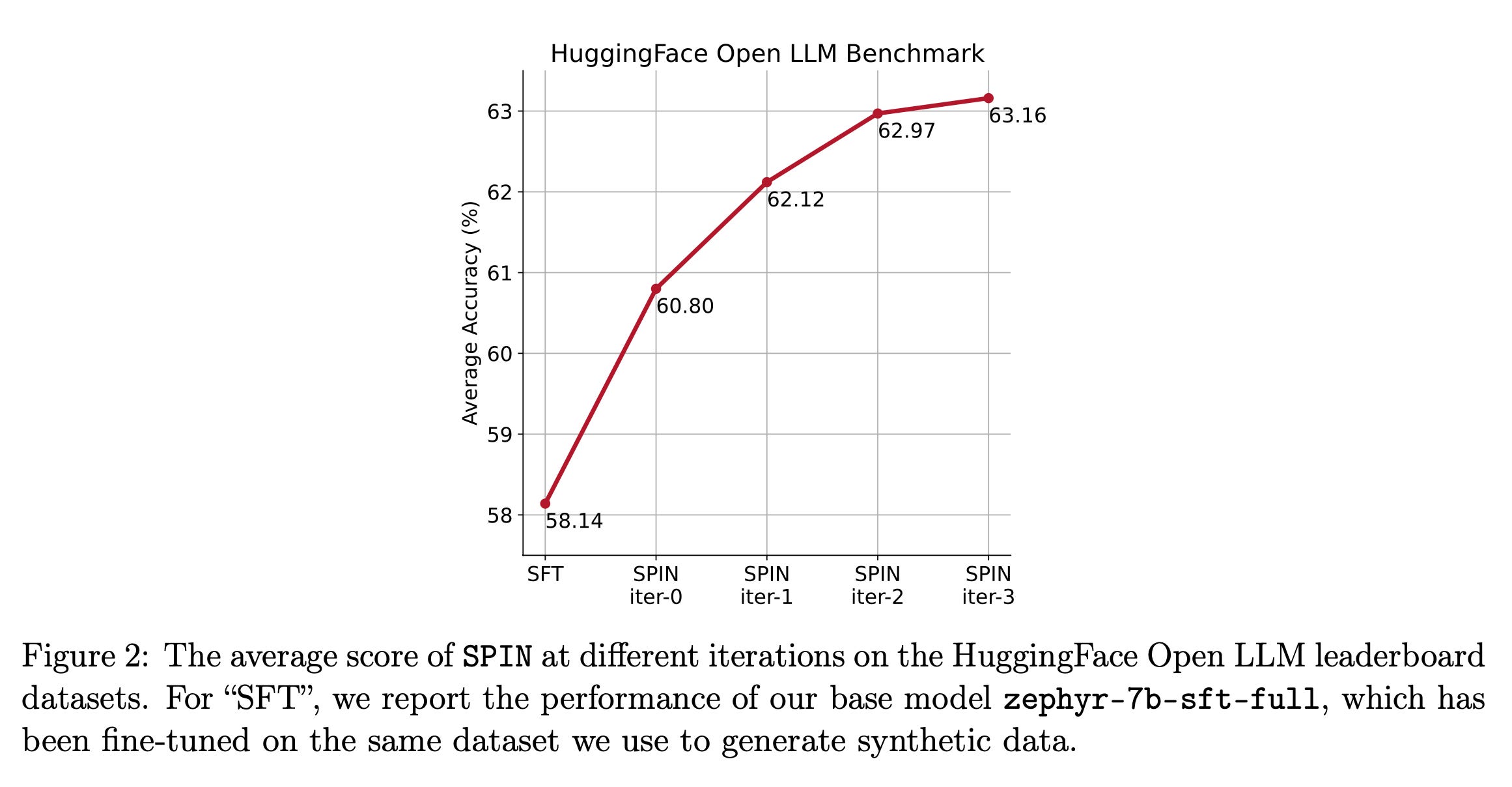
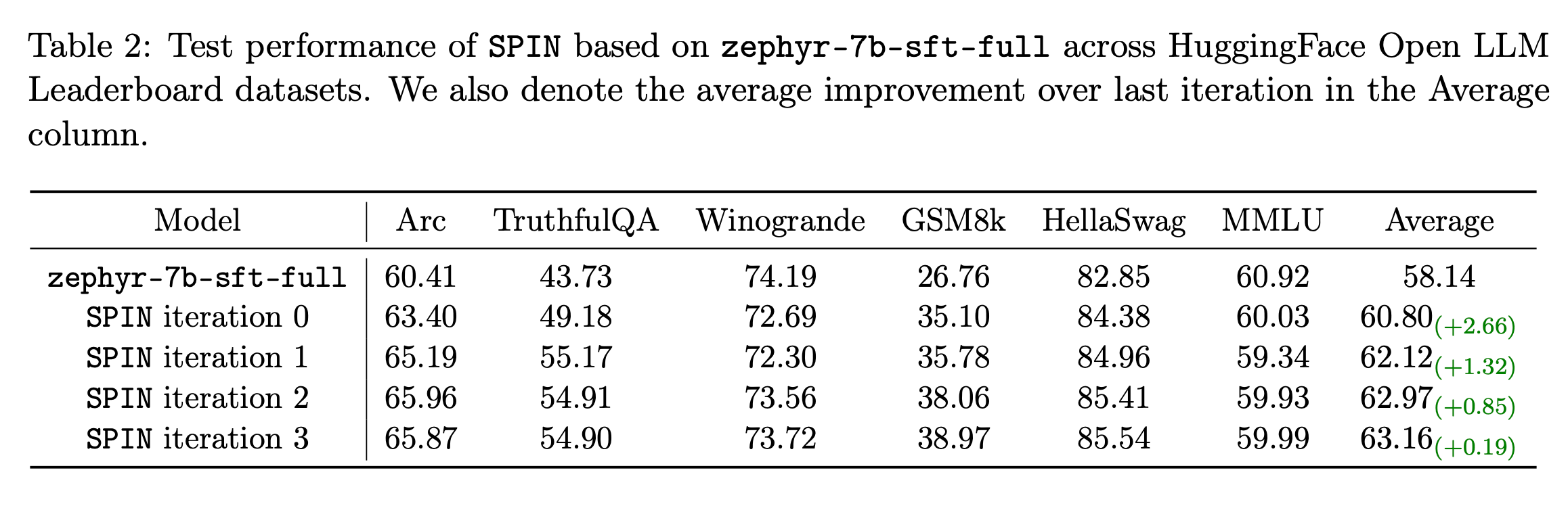
According to the paper, SPIN not only improves LLM performance across these benchmarks but also surpasses the effectiveness of models trained using direct preference optimization with additional GPT-4 preference data.
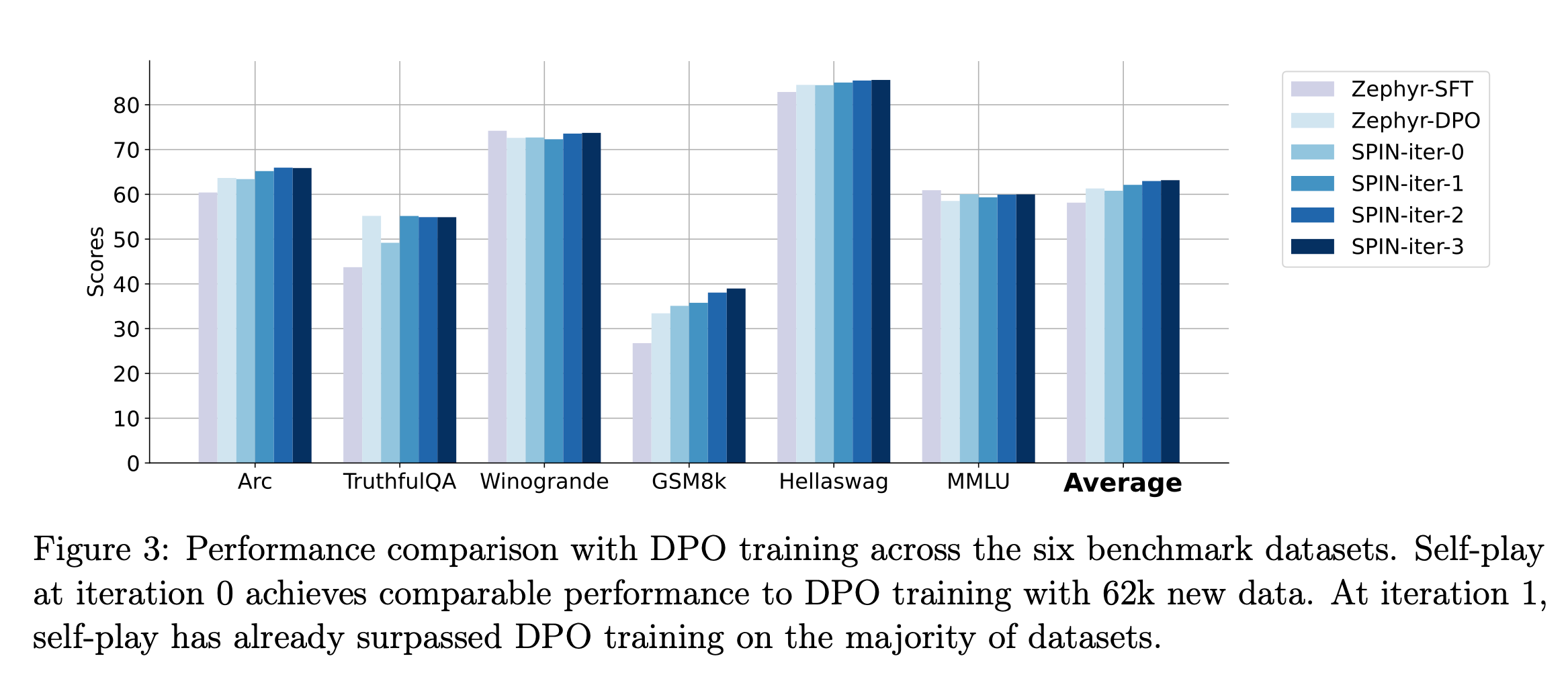
The paper suggests that the self-play methodology of SPIN could be key to achieving human-level performance in language models, bypassing the need for expertly curated training datasets.
TinyLlama: An Open-Source Small Language Model

TinyLlama, introduced as a compact yet powerful language model with only 1.1 billion parameters and has been pretrained on about 1 trillion tokens for roughly 3 epochs. It builds upon the architecture and tokenizer of Llama 2, and incorporates advancements like FlashAttention, resulting in enhanced computational efficiency. Despite its relatively modest size, TinyLlama showcases exceptional performance in various downstream tasks, surpassing the capabilities of similar-sized open-source language models like OPT-1.3B and Pythia- 1.4B. Emphasizing accessibility and community contribution, the authors have made TinyLlama's model checkpoints and code publicly available on GitHub, inviting further exploration and development in the field.
Pretraining
Pretraining data
TinyLlama was pretrained using a carefully curated mix of natural language and code data. The natural language data was sourced from SlimPajama, which is a cleaner and deduplicated variant of the RedPajama corpus. RedPajama is an open-source project aimed at replicating Llama's pretraining data, containing over 1.2 trillion tokens.
For code data, TinyLlama used the Starcoder dataset, encompassing around 250 billion tokens from 86 programming languages, including GitHub issues and text-code pairs involving natural languages.
Combining SlimPajama and Starcoder, TinyLlama's pretraining involved approximately 950 billion tokens, with the model undergoing training for about three epochs. During its training phase, the model maintained a ratio of approximately 7:3 between natural language data and code data.
Architecture
TinyLlama utilizes a model architecture similar to Llama 2, incorporating Rotary Positional Embedding (RoPE) to enhance positional understanding within the model. The architecture includes a normalization of inputs before each transformer sub-layer, employing RMSNorm for improved training efficiency. For its activation function, TinyLlama uses SwiGLU, a combination of Swish and Gated Linear Unit. Additionally, the model employs grouped-query attention, featuring 32 heads for query attention divided into 4 groups of key-value heads, a technique that reduces memory usage and speeds up inference while maintaining performance.

Speed Optimizations
TinyLlama incorporates a suite of speed optimizations, crucially integrating Fully Sharded Data Parallel (FSDP) for efficient use of multi-GPU and multi-node setups, and Flash Attention 2 for an optimized attention mechanism. The model uses fused operations including layernorm, cross-entropy loss, and rotary positional embedding, significantly boosting computational throughput. Further, use of fused SwiGLU from xFormers further improves efficiency. This allows the 1.1 billion parameter model to operate within 40GB of GPU RAM. These enhancements enable TinyLlama to reach a training throughput of 24,000 tokens per second per A100-40G GPU, surpassing the training speed of similar models like Pythia-1.0B and MPT-1.3B, as TinyLlama requires considerably fewer GPU hours for training.
Results
TinyLlama was evaluated for its commonsense reasoning on tasks like Hellaswag, OpenBookQA, WinoGrande, ARC-Easy and ARC-Challenge, BoolQ, and PIQA, using the Language Model Evaluation Harness in a zero-shot setting. Its problem-solving capabilities were tested using the InstructEval benchmark, comprising tasks like MMLU (5-shot), BIG-Bench Hard (3-shot), Discrete Reasoning Over Paragraphs (DROP) (3-shot), and HumanEval (zero-shot).
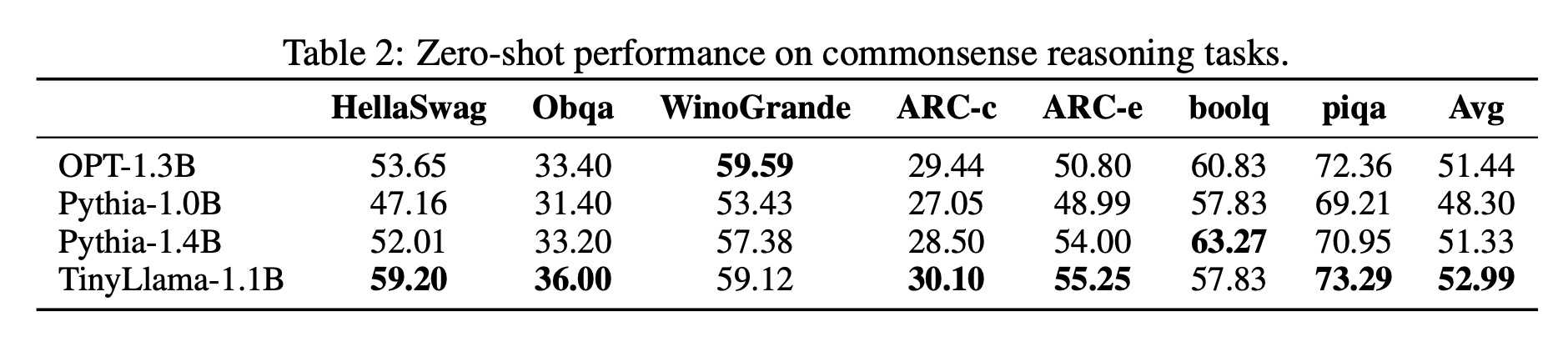
TinyLlama, with its compact architecture and impressive performance, opens up the possibility of deploying advanced language model applications directly on mobile devices. Its lightweight design makes it ideal for experimenting with novel ideas for language models.